Jon Massey - Blog
Jon Massey’s Personal Blog
Chrome, Python and Beautifulsoup, a Powerful Web Scraping Combo
I’ve been doing odd bits of web scraping in various job roles using various technologies (VBA macros in an Excel sheet being a particular low point) for about 15 years and over that time there have been some changes that make things a bit more difficult but the tools available have become orders of magnitudes better. One set of tools I’ve recently enjoyed using on a recent scraping mission is Google Chrome to investigate a page’s markup and the Python programming language along with the Requests, and BeatifulSoup 4 libraries. This post isn’t intended to be a how-to on programming in Python (as I am a mere novice in such regards) or an all-encompassing guide to web scraping but more as a couple of pointers that might help you along the way.
Chrome Dev Tools and Inspect Mode
Most modern browsers contain a built in set of tools to aid web developers inspect the source of web sites and debug their code. Gone are the days of View Source just dumping an entire page’s HTML into a plain text editor, we now have powerful tools for navigation, inspection, editing and profiling a page all within the browser.
If you’ve not used it before, fire up Chrome and right-click somewhere on a web page and select “Inspect”. This will pop open the Dev Tools (either at the side of the screen or the bottom) and will show the inspected element highlighted in the elements view:
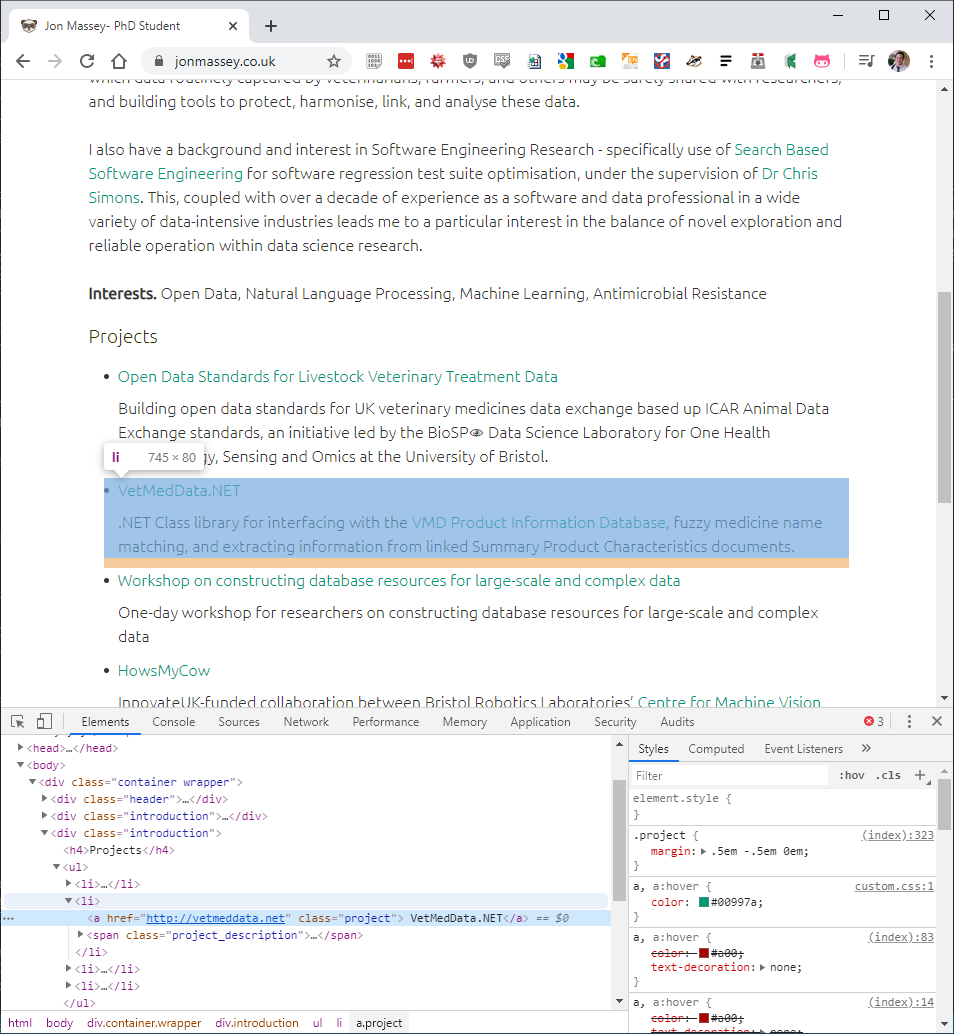
Crucially I’d like to draw your attention to the very bottom of the screen, reading html body div.container.wrapper div.introduction ul li a.project which is the hierarchy of CSS selectors which apply to the element in question. Right-clicking on the element you desire in the Elements view and selecting Copy -> Copy selector will give you a specific as possible a selector which applies to that element, in this case: body > div.container.wrapper > div:nth-child(3) > ul > li:nth-child(2) > a. Both os these pieces of information are a great way to prototype which selectors you need to get the information you desire.
The Utterly Awesome power of CSS selectors
CSS Selectors, as their name suggests are a way of identifying which elements on a page a style element should apply to. Their primary use is within Cascading Style Sheets but we can also use this syntax to identify which elements we wish to scrape data from.
- Element type -
a,div,spanetc. - Class -
.classNamefor all elements of a class orelementType.classNamefor only certain element types- Very useful if classes have semantic information within them, but even ones which only describe the way things should look can be handy
- ID -
#identifierorelementType#identifier- Can be extraordinarily useful if you’re trying to select a very specific element, or wholly useless in the case of meaningless IDs created by a content management system
- Children -
parentElement > childElement- Very useful for working your way down a hierarchy of elements
- Siblings -
~for any sibling+for the next sibling element
A recent example where I made use of all of these is iterating through many pages of search results. The website in question laid out the results in a div helpfully identified as searchResults, or to use the selector parlance div#searchResults. Within this there was an unordered list of results div#searchResults > ul, which contained list items div#searchResults > ul > li that had a link (anchor) to the search result in question div#searchResults > ul > li > a. This selector will select all of the links to the results for on a page of search results - fantastic!
In the case where certain search queries produced many pages of results, I had to use another selector to handle moving through multiple pages. Mercifully, the markup of the page made it really easy to do this, with the search page result menu represented as an undordered list ul#paginationControl with a list item for each page ul#paginationControl > li and a link within each of of those ul#paginationControl > li > a - iterating through this could get me all the results I wanted. Unless, of course there are so many pages that not every page number is shown and the list is abbreviated with a “…”. This is where the sibling selectors really shone - thankfully the “currently selected page number” was identified by a class of currentPage so that it could be displayed in a different colour and by selecting the next sibling I could find the link to the next result page for any given page. Or, to sum it up as a selector ul#paginationControl > li.currentPage + li > a
Try using the Chrome Dev Tools to explore CSS selectors more - you can copy selectors from a page as described above, or by using the search box (or Ctrl+F) in the Elements view of the dev tools to find what elements match a selector you are working on.
Requests and BeautifulSoup
Requests does what it says on the tin and is a library that makes making HTTP requests really easy. Using requests.get(URL) will give you an HTTP response, including a response code (e.g 200 OK, 404 Not Found) and some content. This content is the html-formatted goodness you want to get your hands on, and can be easily passed on to BeautifulSoup for easy parsing. A part of an HTTP request worth a moment of consideration is the User Agent String, which identifies the piece of software making the request. By default, requests properly identifies itself to the web server in question which may or may not be configured to respond properly to this user agent string. Luckily, it is possible to override the headers sent with an http request so one can make requests pretend to be a more common browser expected by a web server:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36'
}
response = requests.get(url, headers=headers)The slightly more esoterically-named BeatifulSoup provides many ways to extract parts of structured documents (primarily, but not just HTML). is most easily used by calling the BeautifulSoup constructor with content of the response you have requested : myPageSoup = BeatifulSoup(response.content). The main methods we can then use are select and select_one to apply our CSS selectors to the page. Select will return a list of elements matching a particular selector, and select_one will return the first or only element matching a selector. A given element can be further queried using .text to get the text within in (including any child elements), .children for an elements child elements, .next_siblings and previous_siblings to move sideways and square-brackets notation to access any attributes e.g. ['href'].
Putting it all together in code
Using the outlined example above:
import requests
from bs4 import BeautifulSoup
baseURL = "https://siteIWantToScrape.com"
searchRequestURL = "/search?bananas+in+pajamas"
resultLinkSelector = "div#searchResults > ul > li > a"
nextPageLinkSelector = "ul#paginationControl > li.currentPage + li > a"
while True:
searchResponse = requests.get(baseURL + searchRequestURL)
if searchResponse.status_code != 200:
print("Request to {} responded with code {}"\
.format(baseURL + searchRequest,searchResponse.status_code))
break
searchResultSoup = BeautifulSoup(searchResponse.content)
resultLinks = searchResultSoup.select(resultLinkSelector)
for resultElement in resultLinks:
print(resultLink['href'])
nextPageLink = searchResultSoup.select_one(nextPageLinkSelector)
if nextPageLink:
searchRequestURL = nextPageLink['href']
continue
break(Not) getting banned
Fundamentally, this comes down to being a good web citizen. If your scraping needs require lots of requests to a web site, consider the impact of making those requests: you may be affecting the availability of that website for other users, or may trigger an automated system to restrict access from your IP address/range. Simple techniques for mitigating this are:
- Delays in your code - wait a while between making requests. Unimpeded, your code could end up making hundreds of requests per second.
- Breaking up the scraping into chunks and spreading out over time period. If you don’t need the data right now then spread it out over a couple of days.
- Proxies/VPNs - use these to make your requests from a diverse range of ip addresses
A final note on Regular Expressions
Back in the bad old days before the rich power of CSS selectors and excellent libraries outlined above, an approach I’ve taken to extract data from web pages is to use Regular Expressions. Regular Expressions, or regexes for short, are an incredibly powerful way of expressing what you want to match and extract from a piece of text. They can also have a propensity to become monstrously, incomprehensibly complex quite rapidly if you’re not careful. For that reason, I strongly recommend using CSS selectors as your first choice for extracting data from web pages, but if the information you require is hidden amongst other text within an element or elements then a judicious use of a regular expression or two is a great way to cleanly extract just that information. I’ve used a tool called Expresso for many years to prototype and debug regexes but there are a great number of excellent online tools that serve the same purpose.